Posted by dausacker on Aug 27, 2011 in
General Software proprietário
Quem de nós, neste mundo cada vez mais tecnológico, nunca fez o download de um qualquer software para uma necessidade especifica do nosso dia-a-dia. Seja de maneira dita “limpa”, seja de maneira dita “suja”. Refiro-me aos utilizadores que possuem a respectiva licença do software ou se simplesmente passam “por cima” da mesma e obtêm o software através de um download ilegal com a respectiva “vacina”.
O que alguns não sabem ou não ligam é às licenças de software. Uma licença de software é a definição de autorização ou restrição de determinadas acções, sobre os direitos de autor do programador que cria o software, concedidas ou impostas aos utilizadores do mesmo.
São muitos os tipos de licença que existem hoje em dia e o intuito deste artigo é esse mesmo, que fiquem de um modo geral a saber quais são e o que se pode ou fazer com eles. Não vou entrar em grandes pormenores apenas algumas considerações básicas.

Neste tipo de licença, toda a cópia, redistribuição (o termo “passar a alguém”), ou modificação são estritamente proibidas, o que pode levar a processos judiciais. Para contornar as restrições anteriormente referidas, deve-se contactar o criador para que este dê permissão para o fazer, ou então adquirir uma licença para cada um dos casos anteriormente descritos.
Neste tipo de licença, encontramos vinculados alguns dos mais conhecidos programas mundiais, caso do Windows, Adobe Photoshop, Adobe Dreamweaver, Adobe Flash, Mac OS, entre outros…
GNU General Public License (GPL)
O GPL é a licença com maior utilização por parte de projectos de software livre, em grande parte pela sua utilização no mundo Linux.
3 grandes restrições que gerem e protegem o software com licença GPL:
- Software livre pode ser distribuído e comercializado por qualquer pessoa, mas o distribuidor tem de avisar o receptor acerca dos termos GPL
- Qualquer pacote de software derivado de software protegido pela GPL, também tem de estar abrangido pela GPL
- Código fonte de todo o software protegido pela GPL tem de estar acessível publicamente
Software livre
O conceito “Software Livre” refere-se a qualquer programa que pode ser usado, copiado, estudado, modificado e redistribuído sem nenhuma restrição. Este conceito opõe-se ao conceito de “software proprietário”, mas não ao termo de “software comercial”. Este tipo de licença, como o próprio nome dá a entender, baseia-se em quatro liberdades:
- Liberdade de executar o programa, para qualquer propósito;
- Liberdade de estudar como o programa funciona e adaptá-lo para as suas necessidades. Para tal o acesso ao código – fonte é necessário.
- Liberdade de redistribuir cópias de modo que você possa ajudar ao seu próximo.
- Liberdade de aperfeiçoar o programa, e libertar os seus aperfeiçoamentos, para que deste modo, toda a comunidade se beneficie deles. Para tal o acesso ao código – fonte é necessário.
Código aberto
Normalmente, gosto mais de utilizar o termo em inglês “open source” e refere-se ao mesmo software chamado de software livre, ou seja aquele que respeita as quatro liberdades anteriormente referidas. A única diferença entre os dois está no discurso. Enquanto o termo “software livre” é usado em questões éticas, direitos e liberdade, o termo “código aberto” é utilizado para discursar sobre o ponto de vista puramente técnico, sem que leve a conflitos de questões éticas.
Software comercial
Software desenvolvido por uma empresa com fins lucrativos com a sua utilização. É de referir que “comercial” e “proprietário” não são o mesmo, pois, a maioria do software comercial é software proprietário mas existe software livre que é comercial, e existe software não-livre e não-comercial (software proprietário que não esta a venda por nenhum preço, apenas existem limitações a nível de modificação do mesmo).
Software gratuito (freeware)
Mais conhecido por freeware é qualquer programa cuja utilização não implica o pagamento de licenças para a sua utilização.
Mas não se enganem que para este tipo de licença que não é necessário o contrato de licenciamento para a sua utilização. Normalmente, ao instalar um software deste tipo, o utilizador deverá concordar com o seu contrato de licenciamento que normalmente acompanha o programa, pois neste podem estar restrições como sendo freeware de uso pessoal, académico, militar e governamental. Pois, não é por ser freeware que ele pode ser utilizado por qualquer um.
Normalmente os programas deste tipo não apresentam o seu código fonte, apenas apresenta o executável. Programas do tipo adware não são considerados gratuitos, mesmo que não seja necessário pagar, pois tem sempre um custo a pagar, nem que seja visualizar a publicidade quer seja o reencaminhado para páginas web, entre outras.
Um exemplo de software gratuito é o Adobe Reader um dos mais populares leitores de fciheiros em formato PDF.
Conclusões
Agora pensem mesmo se será mais fácil andar com cracks daqui para ali, ou se será mais fácil uma simples pesquisa no Google em busca de uma aplicação gratuita com funcionalidades idênticas.
http://joao-nascimento.hostei.com/blog/
Posted by dausacker on Aug 15, 2011 in
General 
Depois que Google e Microsoft trocaram farpas sobre patentes e o Android, surgiu o questionamento: está certo patentear software? Kent Walker, conselheiro-geral do Google, diz que “patentes de software estão meio que atrapalhando o funcionamento da inovação”. Mas qual o real problema com essas patentes?
A ideia das patentes é incentivar a inovação, dando ao criador o direito de uso exclusivo por alguns anos (dezessete nos EUA). Mas há dois grandes problemas. Primeiro, o software já pode ser protegido através de copyright, como um livro ou uma música. Segundo Timothy Lee, da Forbes, as patentes de software são “na maior parte supérfluas“, já que existe outra forma de protegê-lo (veja aqui a diferença entre copyright e patente de software). Segundo, você não precisa necessariamente copiar algo para infringir uma patente de software: “você pode chegar a uma ideia de forma independente e achar que é uma criação sua, mas mesmo que você prove isto, ainda pode estar infringindo a patente”, como lembra Simon Davies, presidente do comitê de tecnologia da CIPA, órgão britânico de advogados de patentes.
Este segundo argumento é defendido por grandes nomes da tecnologia, como Richard Stallman e Marco Arment. Stallman diz: “se você for um desenvolvedor de software, você geralmente será ameaçado uma patente por vez”. Arment lembra que, apesar de patentes estimularem a inovação, este não é o caso no software. As patentes criam um campo minado que cada desenvolvedor de software precisa atravessar.
Há quem discorde, é claro. Nilay Patel, especialista em Direito do This Is My Next, é cético quanto a esta teoria do “campo minado” de patentes. Ele argumenta que as patentes de software são boas porque, quando elas expiram, caem em domínio público e o dono da patente é obrigado a divulgar todos os detalhes, inclusive a melhor forma de construir a invenção. Por exemplo, o algoritmo PageRank do Google, um dos maiores segredos da empresa, estará em domínio público em 2018, quando vence a patente. (Eles com certeza aperfeiçoaram o algoritmo, então isto não deve ser problema para eles.)
O engenheiro de software Lukas Mathis rebate os dois argumentos. Ele reuniu uma lista com uma dúzia de patentes de software genéricas o bastante para serem facilmente violadas. E rebate o argumento do domínio público, já que as patentes são descritas com forte jargão jurídico – portanto, não fica claro o benefício que um programador tiraria delas.
Um problema americano

Patentes de software não são concedidas no mundo todo. Na União Europeia, por exemplo, software não pode ser patenteado. No Brasil, vale o mesmo: uma invenção que não possa ser fabricada ou produzida não é patenteável. Existem exceções: por exemplo, caso o software esteja bastante integrado ao hardware, a patente é concedida ao conjunto. (Isso vale para maquinário de indústria, por exemplo.)
O maior problema está nos EUA, onde as patentes de software foram gradualmente sendo aceitas ao longo das décadas de 80 e 90. Lá, existia a mesma exigência de software integrado ao hardware para conceder patente, mas a exigência foi sendo relaxada. Como explica Nilay Patel, “o ‘componente de hardware’ requerido foi dissolvido em nada mais que uma estrutura de dados escrita na memória física de um computador”. Agora, mais de 15.000 patentes de software são aprovadas anualmente.
E o USPTO, órgão americano que concede patentes, tem hoje diversos problemas. Dan Ravicher, diretor-executivo da Public Patent Foundation, lembra que o órgão é financiado pela aplicação de patentes – ou seja, ele é “incentivado financeiramente a emitir patentes“. E isso vale mesmo para os examinadores de patente, que ganham mais à medida que fecham a análise de cada patente. Só que, segundo Ravicher, é mais fácil aprovar uma patente do que rejeitá-la: negar um pedido de patente geralmente envolve lidar com volumosos contra-argumentos de quem fez o pedido. Por fim, como lembra Marco Arment, o USPTO já mostrou que não tem a capacidade de aprovar patentes de software de forma responsável: a Suprema Corte americana já criticou duramente o órgão por não usar bom senso ao emitir uma patente de software, por exemplo.
O certo é banir?

Resumindo: o consenso é de que as patentes atrapalham o desenvolvimento de software, em vez de estimular a inovação. Então vamos nos livrar delas! Não tão rápido: Timothy Lee, da Forbes, lembra que “invalidar patentes de software a este ponto seria intensamente controverso” – seriam centenas de milhares de patentes simplesmente anuladas, em um só golpe. É meio irrealista querer que isto aconteça de vez.
Podemos pensar em uma solução gradual, no entanto. Nilay Patel lembra que, nos EUA, não existe uma categoria separada para patentes de software: programas, algoritmos e elementos de interface são patenteados da mesma forma que máquinas e dispositivos, apesar de custarem menos para criar e distribuir. E o monopólio para explorar uma patente dura 17 anos nos EUA, uma eternidade no que se trata de software.
Nilay propõe, então, criar uma categoria “patente de software”, definindo-a com clareza na lei, e limitando seu tempo de duração. Jeff Bezos, da Amazon, sugeriu em 2000 que patentes de software deveriam durar de três a cinco anos no máximo.
Mas, como lembra Timothy Lee, “invalidar essas patentes seria boa política e também uma boa lei”. E isso só pode acontecer quando se tornar claro ao público que as patentes de software prejudicam os desenvolvedores, em vez de ajudá-los. Esta atitude vem inclusive de grandes empresas: no polêmico post que acusa a Apple, Microsoft e outras de realizarem “uma campanha hostil e organizada contra o Android”, o Google diz estar trabalhando com o Departamento de Justiça americano para investigar abusos de patente por outras empresas.

Vale lembrar que acabar com patentes de software não resolve por completo as brigas judiciais que vimos nos últimos meses. Por exemplo, a Apple acusa a Samsung de 16 violações, mas delas apenas sete são relacionadas a patentes de software – a maioria se trata de como a Samsung aparentemente copiou a Apple no hardware (violando patentes) e nos elementos de interface (violando marcas registradas) e embalagem (violando trade dress/conjunto-imagem). No entanto, em outros casos – como Apple vs. HTC, considerado um ataque ao Android – a maior parte das violações é de patentes de software, como o “deslize para destravar” e o efeito de “salto” quando você chega ao fim de uma página ou lista no iOS. Mesmo o Google não é tão inocente, com patentes de software questionáveis, como a patente pelos Google Doodles. Pelo visto, é melhor que essas patentes jamais tivessem existido.
Por Felipe Ventura
Posted by dausacker on Aug 4, 2011 in
General Introdução

Estudar sobre a história da informática permite entender melhor como os PCs atuais funcionam, já que uma coisa é consequência da outra. Do ENIAC, construído em 1945, até os processadores modernos, tivemos um longo caminho. Este guia resume a história da informática, das válvulas e relês até o 368 passando pelos computadores das décadas de 50, 60 e 70, os primeiros computadores pessoais, o surgimento dos PCs, a história dos sistemas operacionais, curiosidades e a concorrência entre o Mac e o PC.
Embora os eletrônicos sejam uma tecnologia relativamente recente, com menos de um século, a história dos computadores começou muito antes.
Em 1901 um estranho artefato de bronze datado de 100 A.C. foi encontrado no meio dos destroços de um antigo navio romano que naufragou próximo à costa da Grécia. Ele era um pouco maior que uma caixa de sapatos e aparentava ter partes móveis, mas a oxidação transformou tudo em uma peça só, o que tornou a identificação quase impossível:

Em 2006 foi descoberto que ele era, na verdade, um computador mecânico, destinado a calcular o movimento dos astros e prever eclipses, cujas engrenagens competiam em sofisticação com o trabalho de relojoeiros da era moderna.
Até mesmo os Astecas (que sequer usavam ferramentas de metal) desenvolveram máquinas de calcular destinadas a calcular impostos, que eram baseadas em cordas e polias. Infelizmente não se sabe muito sobre o funcionamento delas, já que foram todas destruídas pelos colonizadores espanhóis, que viriam a entender a utilidade das calculadoras apenas alguns séculos depois…
No século XIX, o matemático inglês Charles Babbage trabalhou na “Analytical Engine”, que, caso tivesse sido realmente construída, teria sido o primeiro computador moderno. Embora fosse inteiramente baseada no uso de engrenagens, ela seria alimentada através de cartões perfurados (que viriam a ser a mídia básica de armazenamento de dados durante as décadas de 50, 60 e 70), teria memória para 1000 números de 50 dígitos decimais cada um (equivalente a pouco mais de 20 KB no total) e seria capaz de executar operações matemáticas com uma complexidade bem maior que a dos primeiros computadores digitais (embora em uma velocidade mais baixa, devido à natureza mecânica). Como se não bastasse, os resultados seriam impressos em papel (usando um sistema similar ao das máquinas de datilografar), antecipando o uso das impressoras.
É bem provável que a Analytical Engine pudesse ter sido realmente construída usando tecnologia da época. Entretanto, o custo seria enorme e o governo Inglês (a única organização com poder suficiente para financiar o desenvolvimento na época) não se mostrou muito interessado no projeto.
Entretanto, uma versão mais simples, a “Difference Engine” foi construída em 1991 por uma equipe do Museu de Londres, que se baseou nos projetos de Babbage. Apesar do atraso de mais de um século, ela funcionou como esperado:

Outros projetos de calculadoras mecânicas mais simples foram muito usados ao longo do século XIX e na primeira metade do século XX. O ápice da evolução foi a Curta, uma calculadora mecânica portátil lançada em 1948. Ela é capaz de realizar operações de soma, subtração, multiplicação, divisão e basicamente qualquer outro tipo de operação matemática a partir de combinações de operações simples (potenciação, raiz quadrada, etc.), tudo isso em um dispositivo inteiramente mecânico, do tamanho de um saleiro:

A Curta foi bastante popular durante as décadas de 50, 60 e 70 (foram produzidas nada menos de 140.000 unidades, vendidas principalmente nos EUA e na Alemanha), e o formato, combinado com o barulho característico ao girar a manivela para executar as operações rendeu o apelido de “moedor de pimenta”. Ela era usada por engenheiros, pilotos, matemáticos e muitas universidades as usavam nas cadeiras de cálculos.
A Curta era composta por um total de 605 peças e usava um sistema bastante engenhoso, onde você inseria o número através de um conjunto de 8 chaves laterais (uma para cada dígito decimal), selecionava a operação usando uma chave lateral e executava o cálculo girando a manivela superior, uma vez para cada operação (para multiplicar um número por 4, por exemplo, você a giraria 4 vezes).
Para operações com valores maiores (como multiplicar 57.456.567 por 998) existia um segundo contador na parte superior, que servia como um multiplicador de rotações (1, 10, 100, 1000, etc.). Com isso, em vez de girar 998 vezes, você selecionaria o número 4 (multiplicador 1000), giraria uma vez para inserir o valor, mudaria o contador de volta para o 1, colocaria a chave de operação na posição de subtração, giraria a manivela mais duas vezes para reduzir até o 998, moveria a chave de operação de volta à posição original e giraria a manivela mais uma vez para executar a operação.
Os resultados eram exibidos através de um visor na parte superior, que tinha capacidade para 11 dígitos (as calculadoras de bolso atuais trabalham com apenas 8 dígitos!) e, embora fosse complicada de usar em relação a uma calculadora atual, era bastante confiável e usuários experientes eram capazes de executar cálculos com uma velocidade impressionante. Como se não bastasse, em 1953 foi lançada a Curta Type II, uma versão maior, que permitia inserir números de até 11 dígitos e exibia resultados com até 15 dígitos.
Se ficou curioso, você pode encontrar um simulador em flash que simula uma Curta Type I no http://www.vcalc.net/curta_simulator_en.htm. Outro simulador interessante é o YACS (disponível no http://members.chello.nl/o.veenstra3/) onde você pode ver um modelo em 3D das engrenagens. Você encontra também algumas fotos reais de uma Curta desmontada no http://www.vcalc.net/disassy/.
Mesmo com a introdução das calculadoras eletrônicas, a Curta continuou sendo usada por muitos, já que era muito mais leve e era capaz de trabalhar com números maiores que os suportados pela maioria das calculadores eletrônicas. Pesquisando no Ebay, é possível encontrar algumas unidades funcionais da Curta à venda mesmo nos dias de hoje.
Apesar de impressionarem pela engenhosidade, calculadoras mecânicas como a Curta e computadores mecânicos como a Analytical Engine acabaram se revelando um beco sem saída, já que as engrenagens precisam ser fabricadas individualmente e existe um limite para o nível de miniaturização e para o número de componentes. Uma Curta não pode ir muito além das operações básicas e a Analytical Engine custaria o equivalente ao PIB de um pequeno país para ser construída. Uma nova tecnologia era necessária e ela acabou se materializando na forma dos circuitos digitais.
No final do século XIX, surgiu o relé, um dispositivo eletromecânico, formado por um magneto móvel, que se deslocava unindo dois contatos metálicos. O relé foi muito usado no sistema telefônico, no tempo das centrais analógicas. Nas localidades mais remotas, algumas continuam em atividade até os dias de hoje.
relé do início do século XX
Os relés podem ser considerados como uma espécie de antepassados dos transistores. Suas limitações eram o fato de serem relativamente caros, grandes demais e, ao mesmo tempo, muito lentos: um relé demora mais de um milésimo de segundo para fechar um circuito.
Apesar disso, os relés são usados até hoje em alguns dispositivos. Um exemplo são os modems discados, onde o relé é usado para ativar o uso da linha telefônica, ao discar. Eles são usados também em estabilizadores (geralmente nos modelos de baixo custo), onde são os responsáveis pelos “clicks” que você ouve durante as variações de tensão.
O fato de usar relés e fazer barulho, não é um indício de qualidade (muito pelo contrário), mas infelizmente muitas pessoas associam isso com o fato do aparelho estar funcionando, o que faz com que produtos de baixa qualidade continuem sendo produzidos e vendidos.
Voltando à história, também no final do século XIX, surgiram as primeiras válvulas. As válvulas foram usadas para criar os primeiros computadores eletrônicos, na década de 40.
As válvulas têm seu funcionamento baseado no fluxo de elétrons no vácuo. Tudo começou numa certa tarde quando Thomas Edison, inventor da lâmpada elétrica, estava realizando testes com a sua invenção. Ele percebeu que, ao ligar a lâmpada ao polo positivo de uma bateria e uma placa metálica ao polo negativo, era possível medir uma certa corrente fluindo do filamento da lâmpada até a chapa metálica, mesmo que não existisse contato entre eles. Havia sido descoberto o efeito termoiônico, o princípio de funcionamento das válvulas.
As válvulas já eram bem mais rápidas que os relés (atingiam frequências de alguns megahertz), o problema é que esquentavam demais, consumiam muita eletricidade e se queimavam com facilidade. Era fácil usar válvulas em rádios, que utilizavam poucas, mas construir um computador, que usava milhares delas era extremamente complicado e caro.
Apesar de tudo isso, os primeiros computadores surgiram durante a década de 40, naturalmente com propósitos militares. Os principais usos eram a codificação e a decodificação de mensagens e cálculos de artilharia.
O Eniac
Os primeiro computador digital programável foi o Colossus Mark 1, usado pelos ingleses durante a segunda guerra para decodificar mensagens secretas dos alemães. O Mark 1 foi seguido pelo Colossus Mark 2, que foi o primeiro computador produzido em série, com 10 unidades no total.
O grande problema foi que o Colossus era um projeto secreto. Os inventores não receberam crédito e o design não foi aproveitado em outros computadores, o que tornou o Colossus uma página isolada na história, que só se tornou pública na década de 70.
Por outro lado, os americanos foram muito mais liberais com relação ao anúncio e compartilhamento de informações, o que fez com que o ENIAC (Electronic Numerical Integrator Analyzer and Computer) se tornasse o pontapé inicial na era dos computadores digitais.
O ENIAC foi construído entre 1943 e 1945 e entrou oficialmente em operação em julho de 1946. Ele era composto por nada menos do que 17.468 válvulas, além de 1.500 relés e um grande número de capacitores, resistores e outros componentes.
No total, ele pesava 30 toneladas e era tão volumoso que ocupava um grande galpão. Outro grave problema era o consumo elétrico: um PC típico atual, com um monitor LCD, consome cerca de 100 watts de energia, enquanto o ENIAC consumia incríveis 200 kilowatts. Construir esse monstro custou ao exército Americano 468.000 dólares da época, que correspondem a pouco mais de US$ 10 milhões em valores corrigidos.
Porém, apesar do tamanho, o poder de processamento do ENIAC é insignificante para os padrões atuais, suficiente para processar apenas 5.000 adições, 357 multiplicações ou 38 divisões por segundo. O volume de processamento do ENIAC foi superado pelas calculadoras portáteis ainda na década de 70 e, hoje em dia, mesmo as calculadoras de bolso, das mais baratas, são bem mais poderosas do que ele.
A ideia era construir um computador para quebrar códigos de comunicação e realizar vários tipos de cálculos de artilharia para ajudar as tropas aliadas durante a Segunda Guerra Mundial. Porém, o ENIAC acabou sendo finalizado depois do final da guerra e foi usado nos primeiros anos da Guerra Fria, contribuindo, por exemplo, no projeto da bomba de hidrogênio.

ENIAC (foto do acervo do Exército dos EUA)
Se você acha que programar em C ou em Assembly é complicado, imagine como era a vida dos programadores daquela época. A programação do ENIAC era feita através de 6.000 chaves manuais e, ao invés de ser feita através de teclas, toda a entrada de dados era feita através de cartões de cartolina perfurados, que armazenavam poucas operações cada um.
Uma equipe preparava os cartões, incluindo as operações a serem realizadas, formando uma pilha, outra ia trocando os cartões no leitor do ENIAC, e uma terceira “traduzia” os resultados, também impressos em cartões.
O ENIAC também possuía sérios problemas de manutenção, já que as válvulas se queimavam com frequência, fazendo com que ele passasse boa parte do tempo inoperante. Boa parte das queimas ocorriam durante a ativação e desativação do equipamento (quando as válvulas sofriam um grande stress devido à mudança de temperatura) por isso os operadores logo decidiram mantê-lo ligado continuamente, apesar do enorme gasto de energia.

Válvulas
Vendo essa foto, é fácil imaginar por que as válvulas eram tão problemáticas e caras: elas eram complexas demais. Mesmo assim, na época, as válvulas eram o que existia de mais avançado, permitindo que computadores como o ENIAC executassem, em poucos segundos, cálculos que um matemático equipado com uma calculadora mecânica demorava horas para executar.
O Transistor
Durante a década de 40 e início da de 50, a maior parte da indústria continuou trabalhando no aperfeiçoamento das válvulas, obtendo modelos menores e mais confiáveis. Porém, vários pesquisadores, começaram a procurar alternativas menos problemáticas.
Muitas dessas pesquisas tinham como objetivo o estudo de novos materiais, tanto condutores quanto isolantes. Os pesquisadores começaram então a descobrir que alguns materiais não se enquadravam nem em um grupo nem em outro, pois, de acordo com a circunstância, podiam atuar tanto como isolantes quanto como condutores, formando uma espécie de grupo intermediário que foi logo apelidado de grupo dos semicondutores.
Haviam encontrado a chave para desenvolver o transistor. O primeiro protótipo surgiu em 16 de dezembro de 1947, consistindo em um pequeno bloco de germânio (que na época era junto com o silício o semicondutor mais pesquisado) e três filamentos de ouro. Um filamento era o polo positivo, o outro, o polo negativo, enquanto o terceiro tinha a função de controle:

Primeiro Transistor
Aplicando uma carga elétrica apenas no polo positivo, nada acontecia: o germânio atuava como um isolante, bloqueando a corrente. Porém, quando era aplicada tensão também no filamento de controle, o bloco de germânio se tornava condutor e a carga elétrica passava a fluir para o polo negativo. Haviam criado um dispositivo que substituía a válvula, que não possuía partes móveis, gastava uma fração da eletricidade e, ao mesmo tempo, era muito mais rápido.
O primeiro transistor era muito grande, mas não demorou muito para que esse modelo inicial fosse aperfeiçoado. Durante a década de 1950, o transistor foi aperfeiçoado e passou a gradualmente dominar a indústria, substituindo rapidamente as problemáticas válvulas. Os modelos foram diminuindo de tamanho, caindo de preço e tornando-se mais rápidos. Alguns transistores da época podiam operar a até 100 MHz. Naturalmente, essa era a frequência que podia ser alcançada por um transistor sozinho; nos computadores da época a frequência de operação era muito menor, já que em cada ciclo de processamento o sinal precisa passar por vários transistores.
Entretanto, o grande salto foi a substituição do germânio pelo silício. Isso permitiu miniaturizar ainda mais os transistores e baixar seu custo de produção. Os primeiros transistores de junção comerciais (já similares aos atuais) foram produzidos a partir de 1960 pela Crystalonics, decretando o final da era das válvulas.
A ideia central no uso do silício para construir transistores é que, adicionando certas substâncias em pequenas quantidades, é possível alterar as propriedades elétricas do silício. As primeiras experiências usavam fósforo e boro, que transformavam o silício em condutor por cargas negativas ou em condutor por cargas positivas, dependendo de qual dos dois materiais fosse usado. Essas substâncias adicionadas ao silício são chamadas de impurezas, e o silício “contaminado” por elas é chamado de silício dopado.
O funcionamento de um transistor é bastante simples, quase elementar. É como naquele velho ditado “as melhores invenções são as mais simples”. As válvulas eram muito mais complexas que os transistores e, mesmo assim, foram rapidamente substituídas por eles.
Um transistor é composto basicamente por três filamentos, chamados de base, emissor e coletor. O emissor é o polo positivo, o coletor, o polo negativo, enquanto a base é quem controla o estado do transistor, que como vimos, pode estar ligado ou desligado. Veja como esses três componentes são agrupados em um transistor moderno:
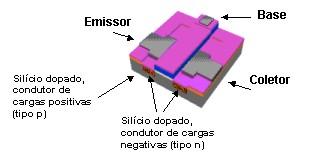
Transistor
Quando o transistor está desligado, não existe carga elétrica na base, por isso, não existe corrente elétrica entre o emissor e o coletor. Quando é aplicada uma certa tensão na base, o circuito é fechado e é estabelecida a corrente entre o emissor e o receptor.
Cada transistor funciona como uma espécie de interruptor, que pode estar ligado ou desligado, como uma torneira que pode estar aberta ou fechada, ou mesmo como uma válvula. A diferença é que o transistor não tem partes móveis como uma torneira e é muito menor, mais barato, mais durável e muito mais rápido que uma válvula.
A mudança de estado de um transistor é feita através de uma corrente elétrica. Cada mudança de estado pode então comandar a mudança de estado de vários outros transistores ligados ao primeiro, permitindo o processamento de dados. Num transistor, essa mudança de estado pode ser feita bilhões de vezes por segundo, porém, a cada mudança de estado é consumida uma certa quantidade de eletricidade, que é transformada em calor. É por isso que quanto mais rápidos tornam-se os processadores, mais eles aquecem e mais energia consomem.
Um 386, por exemplo, consumia pouco mais de 1 watt de energia e podia funcionar sem nenhum tipo de resfriamento. Um 486DX-4 100 consumia cerca de 5 watts e precisava de um cooler simples, enquanto um Athlon X2 chega a consumir 89 watts de energia (no X2 5600+) e precisa de, no mínimo, um bom cooler para funcionar bem. Em compensação, a versão mais rápida do 386 operava a apenas 40 MHz, enquanto os processadores atuais já superaram a barreira dos 3.5 GHz.
Os Primeiros Chips
O salto final aconteceu quando descobriu-se que era possível construir vários transistores sobre o mesmo wafer de silício. Isso permitiu diminuir de forma gritante o custo e tamanho dos computadores. Entramos então na era do microchip.
O primeiro microchip comercial foi lançado pela Intel em 1971 e chamava-se 4004. Como o nome sugere, ele era um processador que utilizava um barramento de dados de apenas 4 bits, incrivelmente lento para os padrões atuais.
Apesar disso, ele processava internamente instruções de 8 bits, o que permitia que ele realizasse operações aritméticas relativamente complexas, apesar do baixo desempenho. A frequência máxima de operação do 4004 era de apenas 740 kHz (ou seja, apenas 740 mil ciclos por segundo) e cada instrução demorava 8 ciclos para ser executada (3 ciclos para carregar os endereços, 2 ciclos para carregar a instrução e mais 3 ciclos para finalmente processá-la), o que fazia com que o 4004 não fosse capaz de processar mais do que 92.500 instruções por segundo.
Em compensação, ele era um chip bastante simples, que era composto por apenas 2300 transistores. Pode parecer piada que cada um deles media 10 micra (10.000 nanômetros, contra os 32 ou 45 nanômetros nos processadores atuais), mas na época ele foi um grande feito de engenharia:

Intel 4004
Embora fosse muito limitado, ele foi muito usado em calculadoras, área em que representou uma pequena revolução. Ele foi também usado em diversos equipamentos científicos e até mesmo na sonda Pioneer 10 (http://www.nasa.gov/centers/glenn/about/history/pioneer.html), lançada pela NASA em 1972. Ela foi a primeira a explorar o sistema solar e continuou a se comunicar com a Terra até 1998, quando a distância se tornou grande demais para que os sinais enviados pela sonda fossem captados.
Mais importante do que todos os feitos do pequeno chip, o sucesso do 4004 mostrou a outras empresas que os microchips eram viáveis, criando uma verdadeira corrida evolucionária, em busca de processadores mais rápidos e avançados, que potencializou todo o avanço tecnológico que tivemos desde então.
Em 1972 surgiu o Intel 8008, o primeiro processador de 8 bits e, em 1974, foi lançado o Intel 8080, antecessor do 8088, que foi o processador usado nos primeiros PCs. Em 1977 a AMD passou a vender um clone do 8080, inaugurando a disputa Intel x AMD, que continua até os dias de hoje.

O 8080 da AMD
O Sistema Binário
Existem duas maneiras de representar uma informação: analogicamente ou digitalmente. Uma música gravada em uma velha fita K7 é armazenada de forma analógica, codificada na forma de uma grande onda de sinais magnéticos de diferentes frequências. Quando a fita é tocada, o sinal magnético é amplificado e novamente convertido em som, gerando uma espécie de “eco” do áudio originalmente gravado.
O grande problema é que o sinal armazenado na fita se degrada com o tempo, e existe sempre uma certa perda de qualidade ao fazer cópias. Ao tirar várias cópias sucessivas, cópia da cópia, você acaba com uma versão muito degradada da música original.
Ao digitalizar a mesma música, transformando-a em um arquivo MP3, você pode copiá-la do PC para o MP3 player, e dele para outro PC, sucessivamente, sem causar qualquer degradação. Você pode perder alguma qualidade ao digitalizar o áudio, ou ao comprimir a faixa original, gerando o arquivo MP3, mas a partir daí pode reproduzir o arquivo indefinidamente e fazer cópias exatas.
Isso é possível devido à própria natureza do sistema digital, que permite armazenar qualquer informação na forma de uma sequencia de valores positivos e negativos, ou seja, na forma de uns e zeros.
O número 181, por exemplo, pode ser representado digitalmente como 10110101; uma foto digitalizada é transformada em uma grande grade de pixels e um valor de 8, 16 ou 24 bits é usado para representar cada um; um vídeo é transformado em uma sequência de imagens, também armazenadas na forma de pixels, e assim por diante.
A grande vantagem do uso do sistema binário é que ele permite armazenar informações com uma grande confiabilidade, em praticamente qualquer tipo de mídia; já que qualquer informação é reduzida a combinações de apenas dois valores diferentes. A informação pode ser armazenada de forma magnética, como no caso dos HDs; de forma óptica, como no caso dos CDs e DVDs ou até mesmo na forma de impulsos elétricos, como no caso dos chips de memória Flash.

Cada um ou zero processado ou armazenado é chamado de “bit”, contração de “binary digit” ou “dígito binário”. Um conjunto de 8 bits forma um byte, e um conjunto de 1024 bytes forma um kilobyte (ou kbyte).
O número 1024 foi escolhido por ser a potência de 2 mais próxima de 1000. É mais fácil para os computadores trabalharem com múltiplos de dois do que usar o sistema decimal como nós. Um conjunto de 1024 kbytes forma um megabyte e um conjunto de 1024 megabytes forma um gigabyte. Os próximos múltiplos são o terabyte (1024 gigabytes) e o petabyte (1024 terabytes), exabyte, zettabyte e o yottabyte, que equivale a 1.208.925.819.614.629.174.706.176 bytes. 🙂
É provável que, com a evolução da informática, daqui há algumas décadas surja algum tipo de unidade de armazenamento capaz de armazenar um yottabyte inteiro, mas atualmente ele é um número quase inatingível.
Para armazenar um yottabyte usando tecnologia atual, seria necessário construir uma estrutura colossal de servidores. Imagine que, para manter os custos baixos, fosse adotada uma estratégia estilo Google, usando PCs comuns, com HDs SATA. Cada PC seria equipado com 5 HDs de 2 TB, o que resultaria em pouco menos de 10 terabytes por PC (não seria possível chegar a exatamente 10 terabytes, já que não existem HDs de 2 TB binários no mercado, por isso vamos arredondar).
Estes PCs seriam então organizados em enormes racks, onde cada rack teria espaço para 1024 PCs. Os PCs de cada rack seriam ligados a um conjunto de switchs e cada grupo de switchs seria ligado a um grande roteador. Uma vez ligados em rede, os 1024 PCs seriam configurados para atuar como um enorme cluster, trabalhando como se fossem um único sistema.
Construiríamos então um enorme galpão, capaz de comportar 1024 desses racks, construindo uma malha de switchs e roteadores capaz de ligá-los em rede com um desempenho aceitável. Esse galpão precisa de um sistema de refrigeração colossal, sem falar da energia consumida por mais de um milhão de PCs dentro dele, por isso construímos uma usina hidrelétrica para alimentá-lo, represando um rio próximo.
Com tudo isso, conseguiríamos montar uma estrutura computacional capaz de armazenar 10 exabytes. Ainda precisaríamos construir mais 104.857 mega-datacenters como esse para chegar a 1 yottabyte. Se toda a humanidade se dividisse em grupos de 600 pessoas e cada grupo fosse capaz de construir um ao longo de sua vida, deixando de lado outras necessidades existenciais, poderíamos chegar lá. 😛
Voltando à realidade, usamos também os termos kbit, megabit e gigabit, para representar conjuntos de 1024 bits. Como um byte corresponde a 8 bits, um megabyte corresponde a 8 megabits e assim por diante. Quando você compra uma placa de rede de “1000 megabits” está na verdade levando para casa uma placa que transmite 125 megabytes por segundo, pois cada byte tem 8 bits.
Ao abreviar, também existe diferença. Quando estamos falando de kbytes ou megabytes, abreviamos respectivamente como KB e MB, sempre com o B maiúsculo. Por outro lado, quando estamos falando de kbits ou megabits abreviamos da mesma forma, porém usando o B minúsculo: Kb, Mb e assim por diante. Isso parece só um daqueles detalhes sem importância, mas é uma fonte de muitas confusões. Se um fabricante anuncia a produção de uma nova placa de rede de “1000 MB”, está dando a entender que ela transmite a 8000 megabits e não a 1000.
Hardware x Software

Os computadores são muito bons em armazenar informações e fazer cálculos, mas não são capazes de tomar decisões sozinhos. Sempre existe um ser humano orientando o computador e dizendo a ele o que fazer a cada passo. Seja você mesmo, teclando e usando o mouse, ou, num nível mais baixo, o programador que escreveu os programas que você está usando.
Chegamos então aos softwares, gigantescas cadeias de instruções que permitem que os computadores façam coisas úteis. É aí que entra o sistema operacional e, depois dele, os programas que usamos no dia a dia.
Um bom sistema operacional é invisível. A função dele é detectar e utilizar o hardware da máquina de forma eficiente, fornecendo uma base estável sobre a qual os programas que utilizamos no cotidiano possam ser usados. Como diz Linus Torvalds, as pessoas não usam o sistema operacional, usam os programas instalados. Quando você se lembra que está usando um sistema operacional, é sinal de que alguma coisa não está funcionando como deveria.
O sistema operacional permite que o programador se concentre em adicionar funções úteis, sem ficar se preocupando com que tipo de placa de vídeo ou placa de som você tem. O aplicativo diz que quer mostrar uma janela na tela e ponto; o modelo de placa de vídeo que está instalado e quais comandos são necessários para mostrar a janela, são problema do sistema operacional.
Para acessar a placa de vídeo, ou qualquer outro componente instalado, o sistema operacional precisa de um driver, que é um pequeno aplicativo que trabalha como um intérprete, permitindo que o sistema converse com o dispositivo. Cada placa de vídeo ou som possui um conjunto próprio de recursos e comandos que permitem usá-los. O driver converte esses diferentes comandos em comandos padrão, que são entendidos pelo sistema operacional.
É comum que as várias camadas de softwares que compõem um sistema atual sejam representadas através de uma pirâmide, cuja base é representada pelo BIOS da placa-mãe, kernel do sistema operacional e drivers, e a parte mais alta é representada pelos aplicativos gráficos, com os demais componentes do sistema posicionados nas camadas intermediárias.
Isso deu origem à classificação de linguagens e softwares entre “baixo nível” (os que estão mais diretamente relacionados ao hardware, como o Assembly e os drivers de dispositivo) e “alto nível” (linguagens gráficas ou de scripts, como o Visual Basic .Net ou o Ruby e aplicativos gráficos como o Firefox ou o OpenOffice).
Embora as duas coisas sejam igualmente importantes, existe uma distinção entre o “hardware”, que inclui todos os componentes físicos, como o processador, memória, placa-mãe, etc. e o “software”, que inclui o sistema operacional, os programas e todas as informações armazenadas. Como diz a sabedoria popular, “hardware é o que você chuta, e software é o que você xinga”. 🙂
Carlos E. Morimoto